分布式應(yīng)用中的緩存方案(二) 數(shù)據(jù)庫緩存的實踐與演進
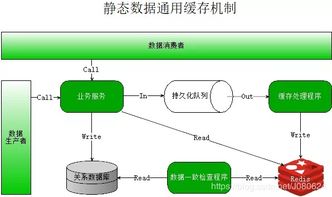
在分布式系統(tǒng)中,數(shù)據(jù)庫緩存作為提升性能、降低延遲的關(guān)鍵技術(shù),其重要性不言而喻。本文將繼續(xù)探討數(shù)據(jù)庫緩存的常見方案、適用場景及演進方向。
一、數(shù)據(jù)庫緩存的核心價值
數(shù)據(jù)庫緩存的核心目標在于減少對底層數(shù)據(jù)庫的直接訪問,通過將熱點數(shù)據(jù)存儲在內(nèi)存中,大幅提升數(shù)據(jù)讀取速度。在高并發(fā)場景下,緩存能夠有效減輕數(shù)據(jù)庫壓力,避免因頻繁I/O操作導(dǎo)致的性能瓶頸。
二、常見的數(shù)據(jù)庫緩存方案
- 查詢緩存(Query Cache)
- 適用于重復(fù)查詢頻繁的場景,如MySQL的查詢緩存機制(注:MySQL 8.0已移除)。
- 優(yōu)點:自動緩存SQL結(jié)果,無需額外編碼。
- 缺點:表數(shù)據(jù)變更時緩存易失效,且在高并發(fā)寫入場景下可能帶來性能開銷。
- 應(yīng)用層緩存(如Redis、Memcached)
- 將緩存置于應(yīng)用層,通過鍵值對存儲熱點數(shù)據(jù)。
- 優(yōu)點:靈活性高,支持豐富數(shù)據(jù)結(jié)構(gòu),可跨服務(wù)共享緩存。
- 缺點:需要顯式管理緩存一致性,增加系統(tǒng)復(fù)雜度。
- 數(shù)據(jù)庫內(nèi)置緩存(如Oracle Buffer Cache、InnoDB Buffer Pool)
- 數(shù)據(jù)庫自身管理的內(nèi)存緩存,用于緩存數(shù)據(jù)頁和索引。
- 優(yōu)點:對應(yīng)用透明,自動優(yōu)化數(shù)據(jù)訪問。
- 缺點:受限于單機內(nèi)存,擴展性較弱。
三、緩存一致性的挑戰(zhàn)與策略
緩存與數(shù)據(jù)庫的數(shù)據(jù)一致性是分布式系統(tǒng)的經(jīng)典難題。常用策略包括:
- 緩存穿透:查詢不存在的數(shù)據(jù)時,可能導(dǎo)致請求直達數(shù)據(jù)庫。可通過布隆過濾器或緩存空值緩解。
- 緩存雪崩:大量緩存同時失效引發(fā)數(shù)據(jù)庫壓力激增。可設(shè)置隨機過期時間或采用熔斷機制。
- 緩存更新策略:如Cache-Aside(先更新數(shù)據(jù)庫再刪除緩存)、Write-Through(同步更新緩存與數(shù)據(jù)庫)等,需根據(jù)業(yè)務(wù)權(quán)衡選擇。
四、演進方向:智能化與多級緩存
- 智能緩存預(yù)熱:基于機器學習預(yù)測熱點數(shù)據(jù),提前加載至緩存。
- 多級緩存架構(gòu):結(jié)合本地緩存(如Caffeine)與分布式緩存(如Redis),形成多層次緩存體系,兼顧速度與擴展性。
- 數(shù)據(jù)庫與緩存融合:如TiDB、AWS Aurora等新型數(shù)據(jù)庫,將緩存機制深度集成,簡化開發(fā)負擔。
五、實踐建議
- 監(jiān)控先行:通過指標(命中率、延遲)持續(xù)評估緩存效果。
- 漸進式優(yōu)化:從核心業(yè)務(wù)開始引入緩存,避免過度設(shè)計。
- 容災(zāi)設(shè)計:緩存故障時需有降級策略(如直接讀庫),保障系統(tǒng)可用性。
數(shù)據(jù)庫緩存并非銀彈,需結(jié)合業(yè)務(wù)特點靈活選型。在“進無止境”的技術(shù)道路上,持續(xù)平衡性能、一致性與復(fù)雜度,方能構(gòu)建穩(wěn)健的分布式系統(tǒng)。
---
本文靈感來源于小小默在CSDN博客的技術(shù)分享,結(jié)合分布式應(yīng)用場景進行了拓展與。
如若轉(zhuǎn)載,請注明出處:http://www.lianaishuo.cn/product/18.html
更新時間:2026-05-22 09:54:43